自动驾驶预测与决策规划(一)
文档维护:Arvin
网页部署:Arvin
▶
写在前面:本文内容是作者在深蓝学院自动驾驶预测与决策规划学习时的笔记,作者按照自己的理解进行了记录,如果有错误的地方还请执政。如涉侵权,请联系删除。
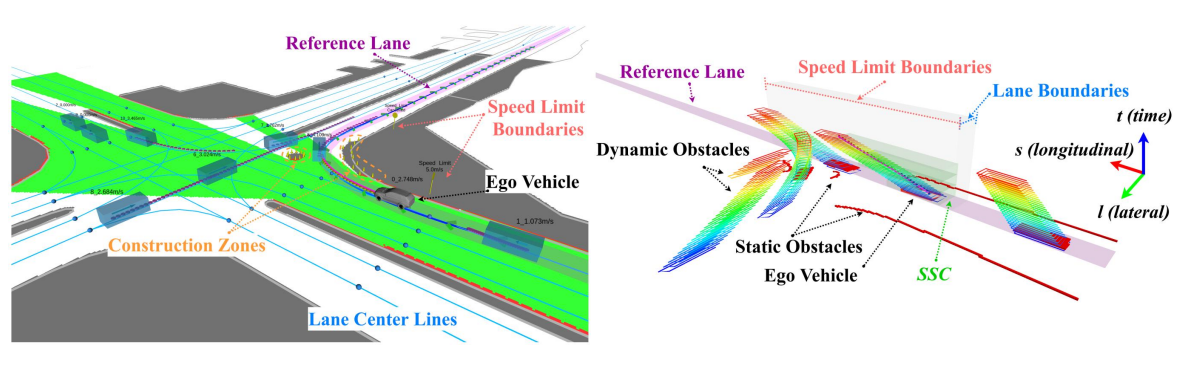
自动驾驶决策规划简介
实验准备
下载nuplan-devkit
在终端中进入希望的安装目录,以主目录为例,运行代码拉取命令:
1 | cd ~ |
安装miniconda
在终端中输入以下命令下载miniconda安装包:
1 | cd ~ |
运行安装包,安装过程中按照指示一直按enter和选择yes即可:
1 | bash Miniconda3-latest-Linux-x86_64.sh |
conda全局初始化将conda的环境路径添加到用户目录的.bashrc文件中,终端每次启动时执行.bashrc添加conda的环境路径,初始化后重新启动终端即可使用conda命令:
1 | ~/miniconda3/bin/conda init bash |
conda换源
装好conda后可以进行换源以提升速度:
1 | cd ~ |
创建conda环境
重启终端,保证终端处于已经下载好的文件夹nuplan-devkit中,运行以下命令:
1 | cd nuplan-devkit |
安装nuplan-devkit
保证终端在nuplan-devkit目录下且nuplan的conda环境处于激活状态,运行以下命令,利用文件夹目录下的两个txt列表进行依赖包的安装,依赖包数量巨大,安装耗时长,可能出现中断现象。因此,在出现中断问题后应多次重复运行以上两行代码,保证所有包安装成功。
1 | conda activate nuplan |
下载nuplan数据集
在nuplan官网注册后即可下载数据集:

注册后能进入如下下载界面,至少下载如图红框的两个数据集: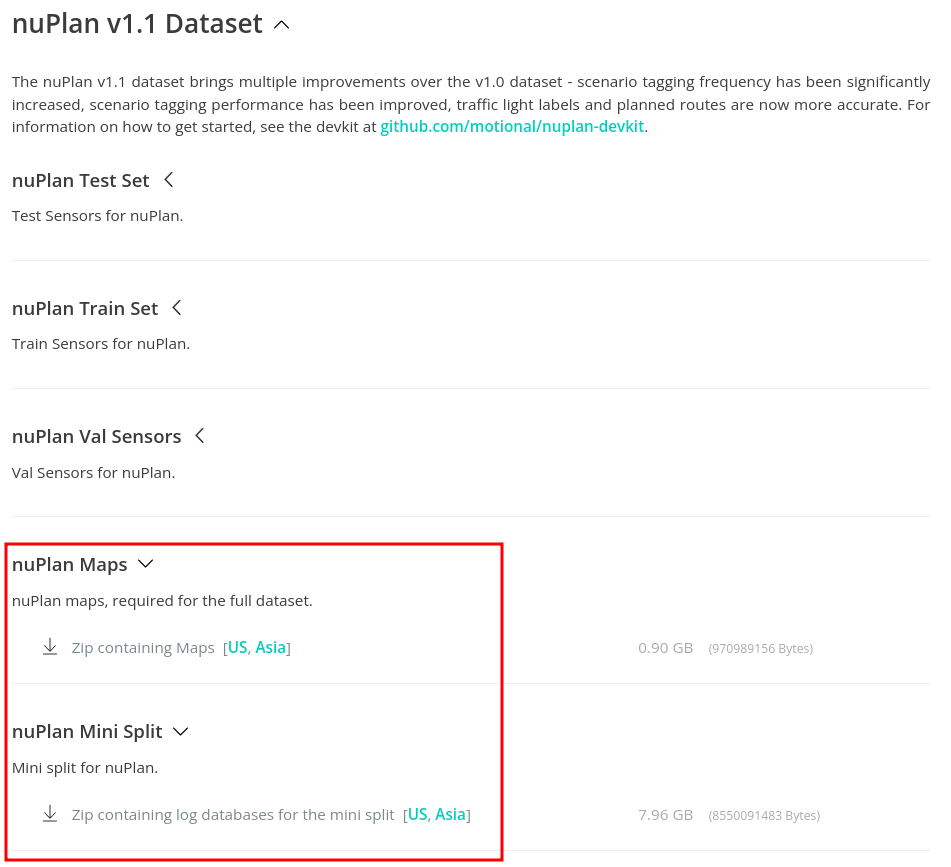
数据下载完成后,应分别解压到相应的文件夹,方便后续下载更大的训练数据集的数据集添加, 如果仅仅进行试用或者学习,我们不必下载trainval数据集,只需要下载maps和mini数据集。因此,在官方推荐文件层次结构的基础上可以进行相应简化,按如下格式存放下载好的maps和mini数据集即可:
1 | ~/nuplan |
环境变量配置
软件包环境变量配置
为了运行nuplan-devkit源码,首先需要添加该环境变量,在~/.bashrc文件中根据nuplan-devkit的实际路径写入如下内容:
1 | 在.bashrc文件中写入 |
数据库环境变量配置
数据库环境变量配置的目的是方便通过代码快速找到数据文件夹的位置,同样需在~/.bashrc中添加以下路径根据数据集文件夹以及地图文件夹的位置进行设置:
1 | # 在.bashrc文件中写入 |
实验效果
场景可视化教程
终端进入nuplan-devkit/tutorials目录,运行jupyter notebook,进入网页选择.ipynb教程文件:
1 | conda activate nuplan |
双击nuplan_scenario_visualization.ipynb进入场景可视化教程,键盘按shift+enter运行,或点菜单栏Run中的Run All Cells选项:
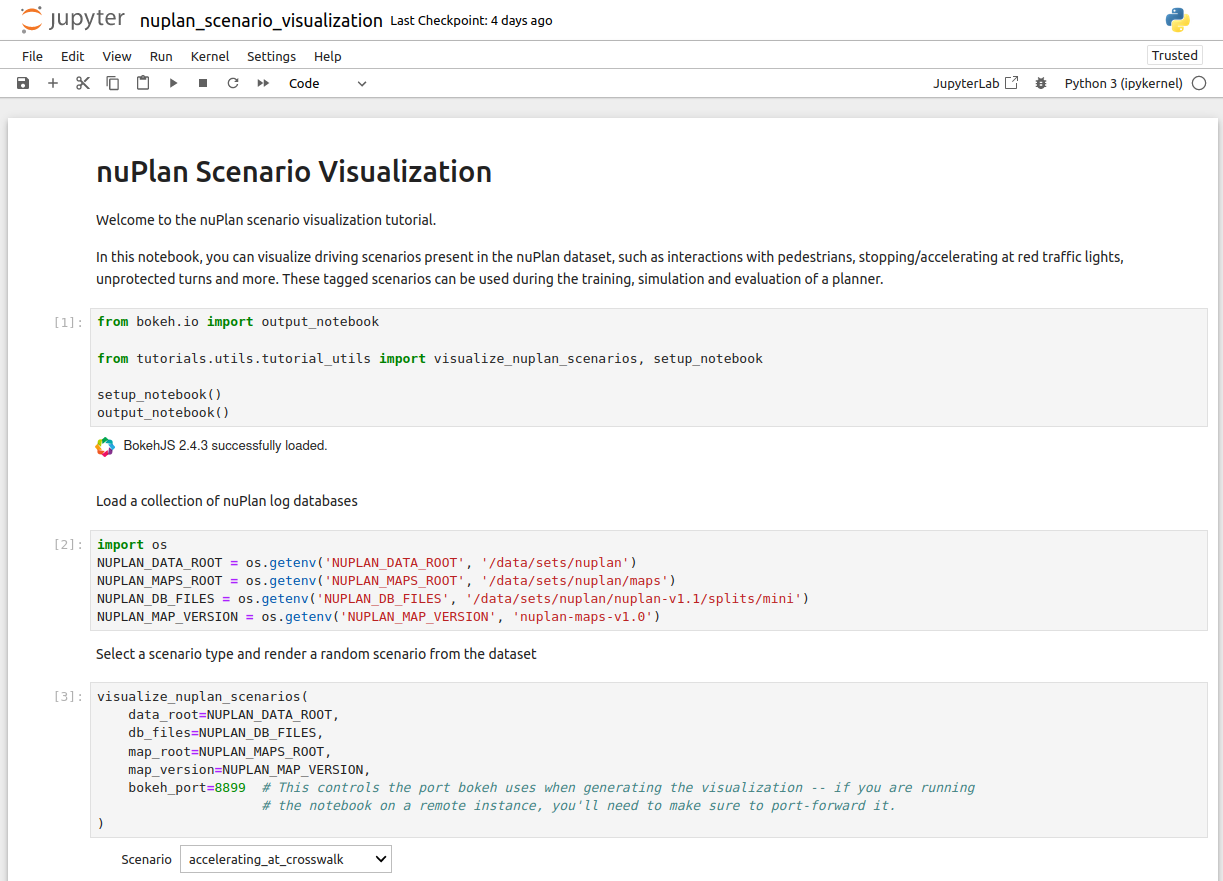
选择场景,例如changing_lane:
开环测评教程
开环测评是指回放所有车辆数据,计算开环分数,主要考量因素为预测轨迹和自车轨迹的位移偏差、航向角偏差等。
在终端中输入如下指令,运行simple_planner的开环仿真程序:
1 | conda activate nuplan |
在终端中输入如下指令,运行nuboard程序,跳转到浏览器:
1 | python nuplan/planning/script/run_nuboard.py |
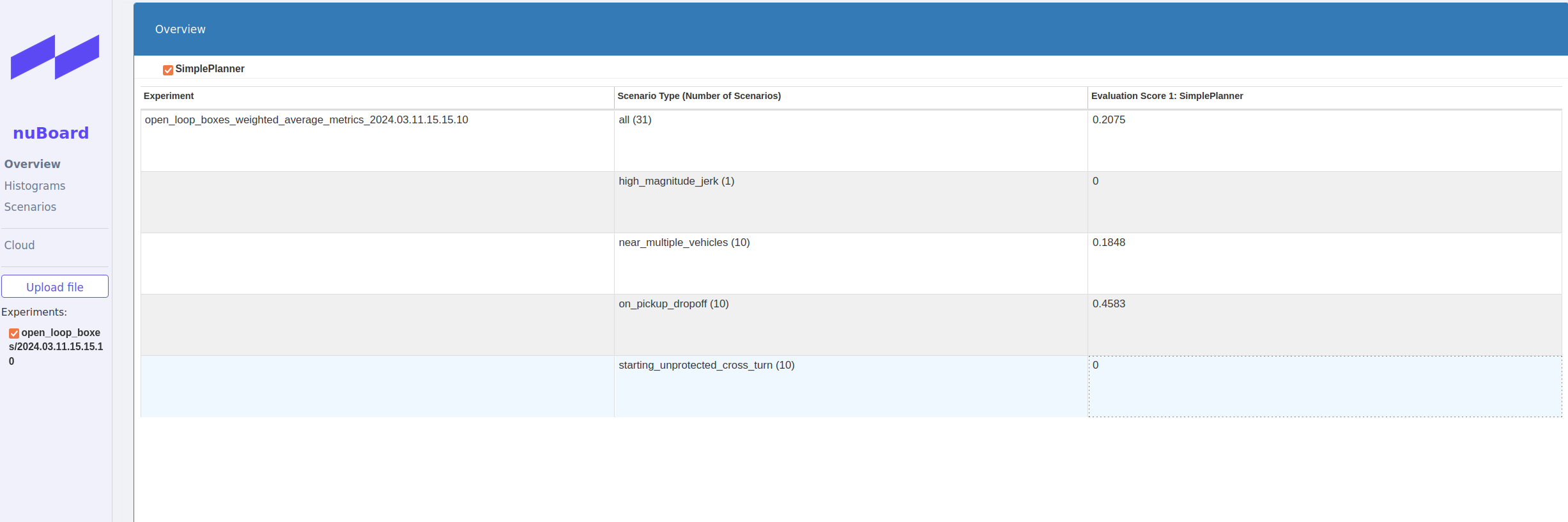
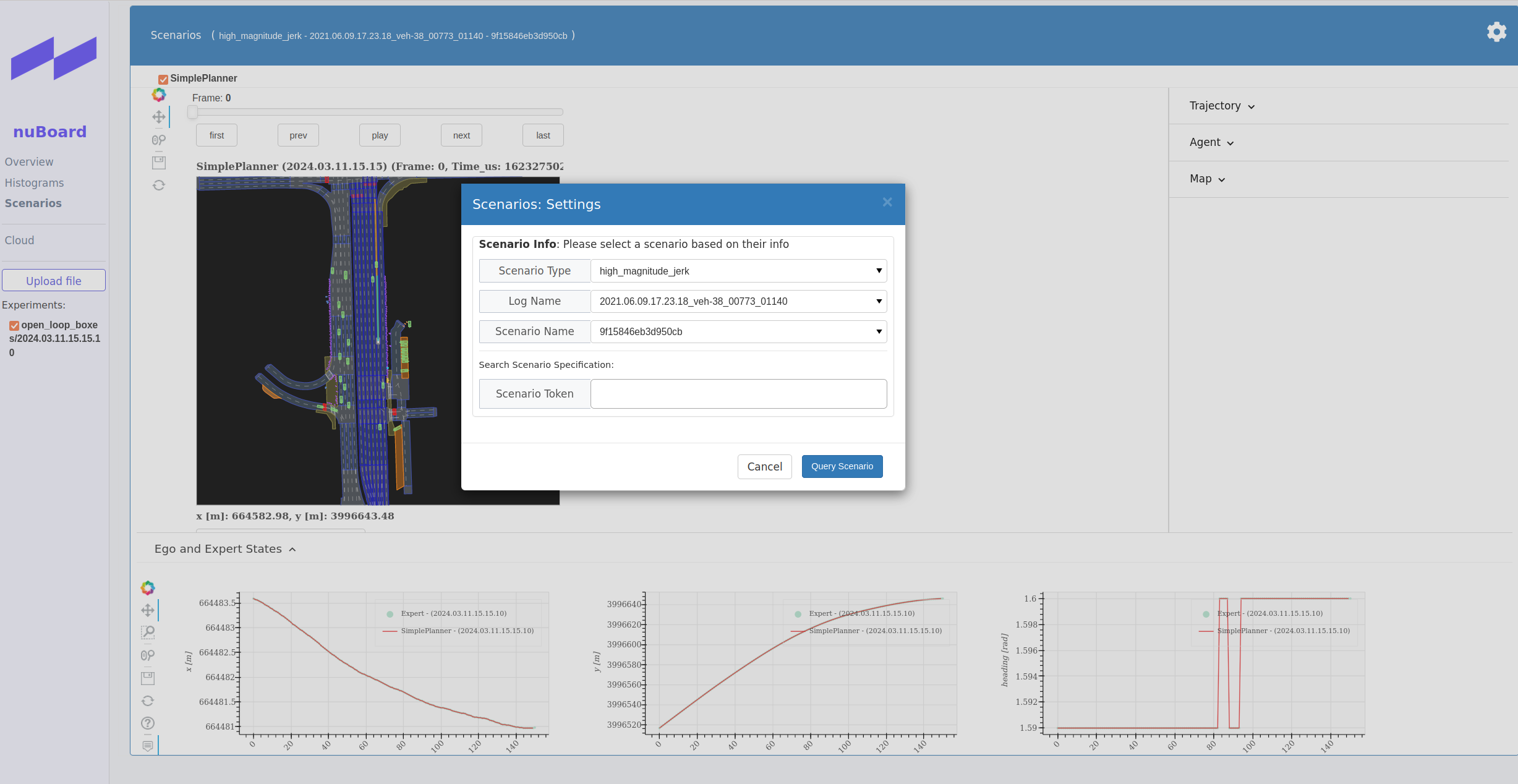
在浏览器中,点击Upload file,选择~/nuplan/exp/exp/simulation/open_loop_boxes/xxxx路径下的nuboard_xxxx.nuboard文件,在网页的Oerview界面中查看开环测评的结果:
在网页的Scenarios界面中查看开环测评的场景信息(点击右上角设置图标选择场景):
无响应闭环测评教程
闭环测评是指自车运行在仿真环境,根据社会车辆是否对自车运动有反应分为:无响应闭环和有响应闭环。
无响应闭环是指社会车辆对自车运动无响应,在终端中输入如下指令,运行simple_planner的无响应闭环仿真程序:
1 | conda activate nuplan |
在终端中输入如下指令,运行nuboard程序,跳转到浏览器:
1 | python nuplan/planning/script/run_nuboard.py |
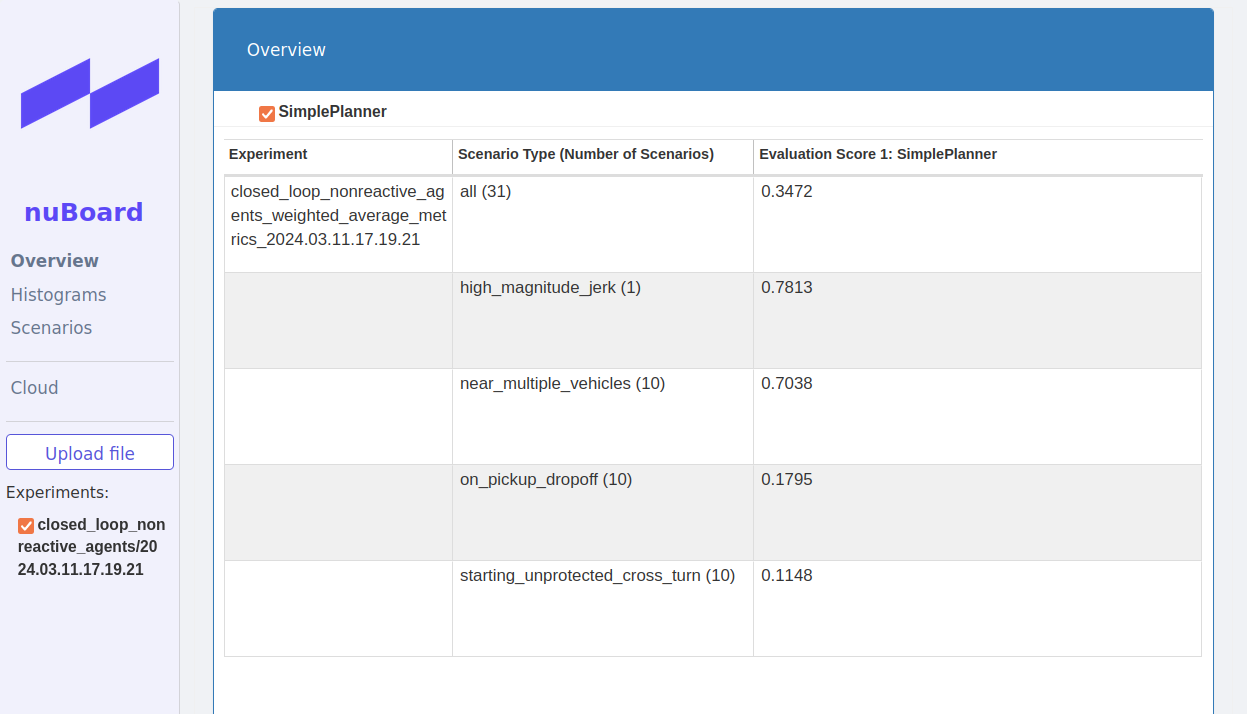
在浏览器中,点击Upload file,选择~/nuplan/exp/exp/simulation/closed_loop_nonreactive_agents/xxxx路径下的nuboard_xxxx.nuboard文件,在网页的Oerview界面中查看无响应闭环测评的结果:
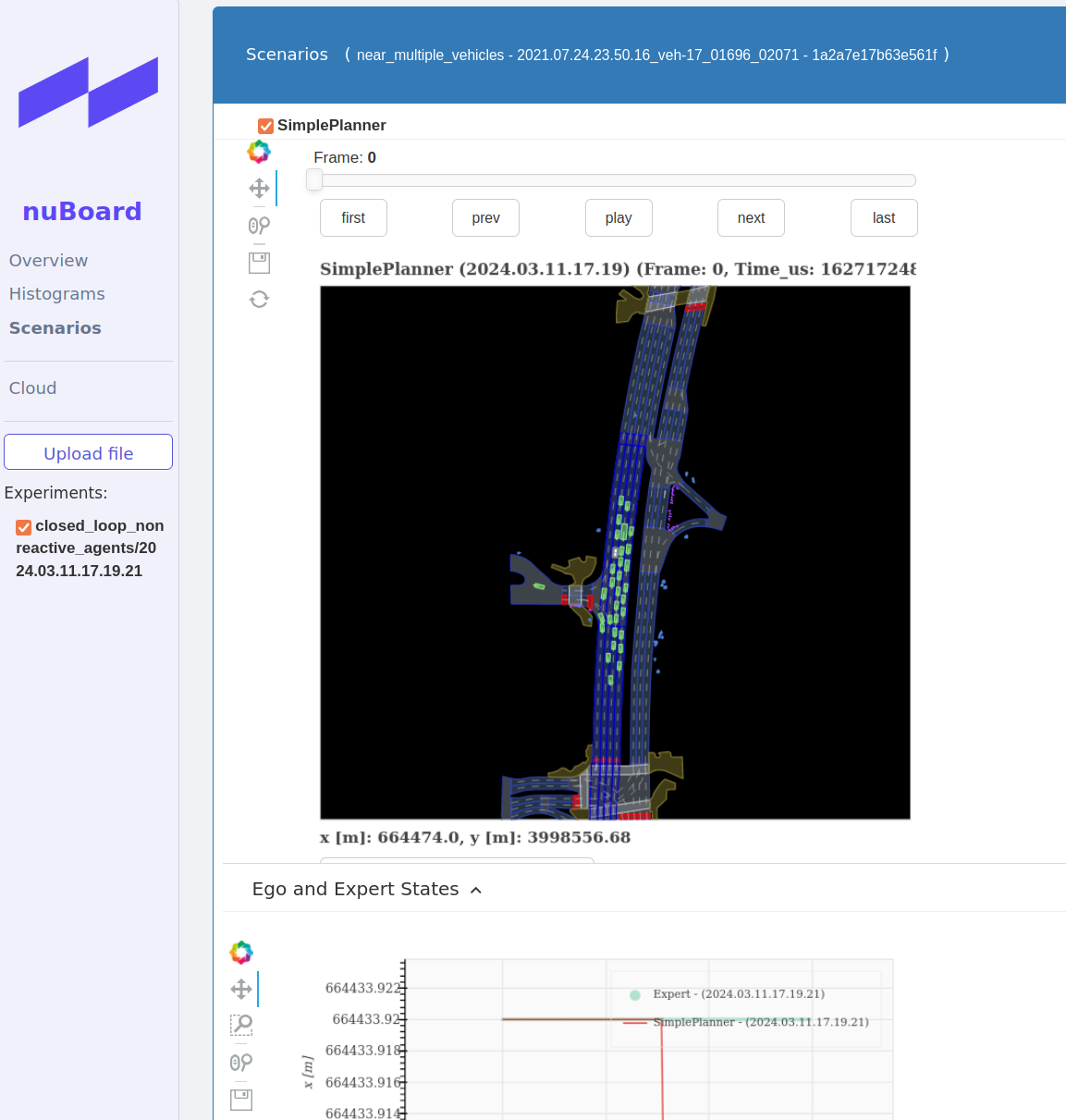
在网页的Scenarios界面中查看无响应闭环测评的场景信息(点击右上角设置图标选择场景):
有响应闭环测评教程
有响应闭环是指社会车辆对自车有响应,在终端中输入如下指令,运行simple_planner的有响应闭环仿真程序:
1 | conda activate nuplan |
在终端中输入如下指令,运行nuboard程序,跳转到浏览器:
1 | python nuplan/planning/script/run_nuboard.py |
在浏览器中,点击Upload file,选择~/nuplan/exp/exp/simulation/closed_loop_reactive_agents/xxxx路径下的nuboard_xxxx.nuboard文件,在网页的Oerview界面中查看有响应闭环测评的结果:
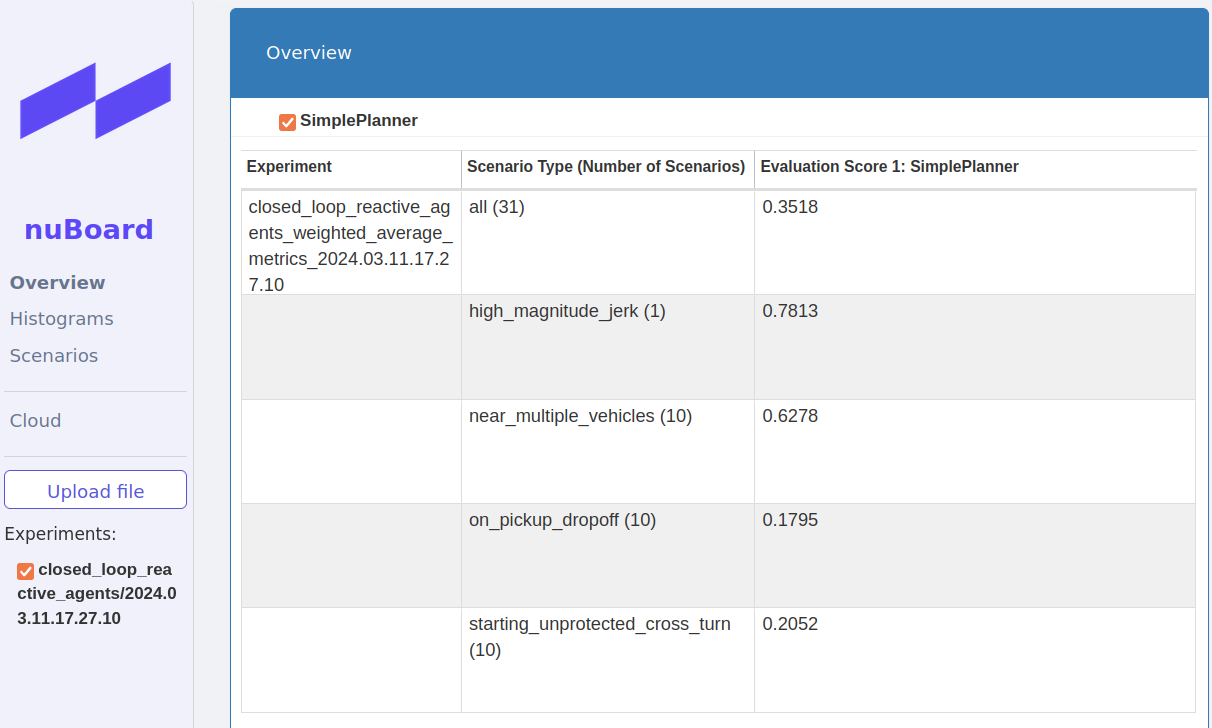
在网页的Scenarios界面中查看有响应闭环测评的场景信息:
其他
cd nuplan-devkit/tutorial然后打开jupyte notebook。双击进入其他框架。
1 | # Main tutorial for anyone who wants to dive right into ML planning. It describes how to 1) train an ML planner, 2) simulate it, 3) measure the performance and 4) visualize the results. |
nuplan-devkit
EgoState类
路径:./nuplan-devkit/nuplan/common/actor_state/ego_state.py
EgoState类是自动驾驶系统中一个核心组件,代表自动驾驶车辆(即ego车辆)的当前状态,包括其位置、朝向、速度、加速度以及其他相关动态属性。以下是该类的主要特点和功能:
主要属性和方法
- 构造函数 (
__init__): 初始化EgoState实例时,需要传入以下参数:car_footprint:CarFootprint对象,表示车辆的几何形状和朝向。dynamic_car_state:DynamicCarState对象,包含车辆的动态状态信息,如速度和加速度。tire_steering_angle: 车辆前轮的转向角度。is_in_auto_mode: 表示车辆是否处于自动驾驶模式。time_point: 时间戳,标识状态的时间点。
- 属性访问器:
is_in_auto_mode: 返回车辆是否处于自动驾驶模式。car_footprint: 获取车辆的几何足迹信息。tire_steering_angle: 获取车辆前轮的转向角度。center: 返回车辆的中心位置,使用StateSE2表示。rear_axle: 返回车辆后轴的位置和朝向,同样使用StateSE2表示。time_point,time_us,time_seconds: 提供对状态时间戳的访问。dynamic_car_state: 获取车辆的动态状态信息。scene_object_metadata: 返回与EgoState相关的场景对象元数据。agent: 将EgoState转换为AgentState对象,便于与环境中的其他代理进行交互。
- 类方法 (
build_from_rear_axle,build_from_center): 提供了基于车辆后轴或车辆中心的不同参数来初始化EgoState的能力。 - 序列化和反序列化 (
serialize,deserialize): 支持将EgoState对象序列化为列表形式,以及从列表形式反序列化回EgoState对象,便于数据的存储和传输。 - 动态状态 (
EgoStateDot): 一个从EgoState继承的子类,主要用于表达EgoState的动态变化,虽然在提供的代码片段中没有具体实现细节。
TimePoint类
TimePoint类是一个用于表示时间点的数据类,主要在时间序列或与时间相关的计算中使用。这个类提供了一种高精度的方式来表示和操作时间,特别是在需要处理与自动驾驶相关的事件和状态时。以下是TimePoint类的关键特点和功能:
属性
time_us: 时间点以微秒为单位,自纪元(Epoch,通常指1970年1月1日)以来的时间。
方法和功能
__post_init__: 初始化后的验证方法,确保时间点是非负的。- 时间转换属性:
time_s: 将时间点从微秒转换为秒。
- 算术操作:
__add__和__radd__: 允许将TimePoint与TimeDuration相加,返回一个新的TimePoint对象,表示相加后的时间点。__sub__: 允许从TimePoint中减去一个TimeDuration或另一个TimePoint,返回一个新的TimePoint对象或TimeDuration对象,分别表示相减后的时间点或两个时间点之间的时间差。
- 比较操作:
__gt__,__ge__,__lt__,__le__,__eq__: 实现了大于、大于等于、小于、小于等于、等于操作,使得TimePoint对象可以直接进行时间比较。
__hash__: 提供了TimePoint对象的哈希方法,使其可以用作字典的键。diff: 计算与另一个TimePoint之间的时间差,返回一个TimeDuration对象,表示两个时间点之间的差异。
OrientedBox类
OrientedBox类表示在平面上代理占据的物理空间。它通常用于自动驾驶系统中来表示车辆、行人等代理的几何形状和位置。以下是OrientedBox类的关键特性和方法:
主要属性
center:StateSE2对象,表示盒子几何中心的位置和朝向。这个属性包含了中心点的(x, y)坐标以及朝向角度(heading)。length: 盒子的长度(沿车辆行进方向)。width: 盒子的宽度(垂直于车辆行进方向)。height: 盒子的高度。
方法和功能
- 构造函数 (
__init__): 接收中心位置、长度、宽度和高度作为参数,初始化OrientedBox实例。 dimensions属性: 返回盒子的尺寸,包括长度、宽度和高度。corner方法: 根据传入的OrientedBoxPointType枚举值(例如,前左、前右、后左、后右、中心等),返回盒子上相应点的坐标。这个方法使用translate_longitudinally_and_laterally函数(假设存在)来计算指定点的位置。all_corners方法: 返回一个包含盒子四个角(前左、后左、后右、前右)的坐标列表。geometry属性: 返回描述OrientedBox的多边形(Polygon),如果还未构建,则懒加载地构建它。这对于执行几何运算,如碰撞检测等,非常有用。from_new_pose类方法: 接收一个OrientedBox实例和一个新的StateSE2姿态,返回一个新的OrientedBox实例,其具有相同的尺寸但位于新的姿态。
StateVector2D类
StateVector2D类代表一个二维向量,它是自动驾驶系统中用于表示位置、速度、加速度等向量属性的基础类。这个类提供了对二维向量操作的基本方法和属性。以下是StateVector2D类的关键特性和功能:
属性
_x和_y: 分别代表向量在x轴和y轴上的分量。_array: 一个numpy数组,包含向量的(x, y)分量。这为向量的数学运算和处理提供了便利。
方法和功能
- 构造函数 (
__init__): 接收两个浮点数x和y作为参数,初始化StateVector2D实例。 __repr__: 返回类的字符串表示,便于调试和打印。__eq__: 重载等于运算符,用于比较两个StateVector2D实例是否相等。- 属性访问器和设置器:
array: 以numpy数组形式返回向量的(x, y)分量,并允许设置新的数组值。x和y: 分别访问和设置向量的x轴和y轴分量。
magnitude: 计算并返回向量的大小(长度)。
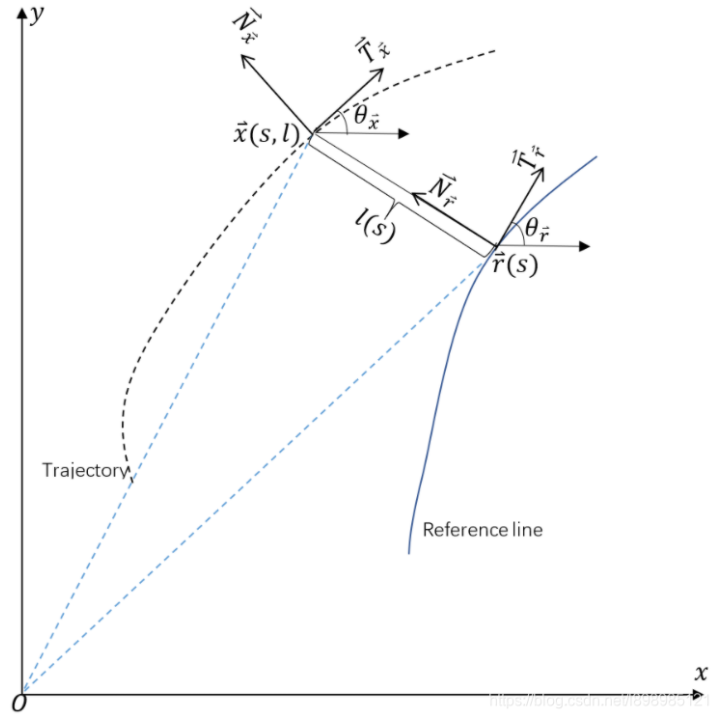
ReferenceLineProvider类
路径:/nuplan-devkit/nuplan/planning/simulation/planner/project2/reference_line_provider.py
ReferenceLineProvider类负责生成和管理参考线,这在自动驾驶规划和导航中是一个关键的概念。参考线通常用于指导自动驾驶车辆的路径规划,表示道路的中心线或车辆的预期行驶路径。这个类通过与BFSRouter(一个假设的路由器类)的交互,从提供的路径中生成参考线。以下是ReferenceLineProvider类的主要特性和方法:
属性
- 路径属性:从
BFSRouter接收的路径信息,包括离散路径点(_discrete_path)、路径的左边界(_lb_of_path)、右边界(_rb_of_path)、路径的累计长度(_s_of_path)和路径上每个点的最大速度(_max_v_of_path)。 - 参考线信息:生成的参考线的各种属性,如左右边界(
_lb_of_reference_line和_rb_of_reference_line)、最大速度(_max_v_of_reference_line)、参考线上的点的累计长度(_s_of_reference_line)、坐标(_x_of_reference_line和_y_of_reference_line)、朝向(_heading_of_reference_line)和曲率(_kappa_of_reference_line)。
方法
_reference_line_generate:该方法接收一个EgoState实例作为输入,并根据车辆当前状态生成参考线。它通过寻找路径上最接近自动驾驶车辆的点,然后在该点的前后进行采样,生成参考线。cal_point_in_line:计算直线上给定x坐标处的y值。这个方法在生成参考线的过程中被用来插值。calculate_heading:计算参考线上各点的朝向。这对于确保自动驾驶车辆沿着正确的方向行驶至关重要。calculate_kappa:计算参考线的曲率。曲率的计算对于理解道路的弯曲程度和规划相应的转向策略很重要。get_boundary:根据给定的一组累积长度(s_set),返回对应的左右边界值。这个方法对于判断车辆是否偏离预期路径有帮助。
基于模型的预测方法
其实包含基本的基于模型的预测方法,还有一些基于learning的预测方法
定速度预测
一维匀速运动模型
目标做匀速直线运动,加速度为0。
现实中速度会有轻微扰动,可视为具有高斯分布的噪声。
一维状态向量
一维连续Constant Velocity模型:
常用离散形式:
其中$T$是采样时间。
二维匀速运动模型
二维状态向量:
二维连续Constant Velocity模型:
二维离散Constant Velocity模型:
其中$T$是采样时间。
定曲率预测
匀速圆周运动状态向量(转弯角速度已知):
匀速圆周运动离散模型:转角变化率$\delta$恒定
| 定速度预测 | 定曲率预测 |
|---|---|
| 适用于速度变化不大的场景 | 适用于曲线路径,汽车转弯的情况 |
| 预测精度不高 | 预测精度稍高 |
| 在速度或方向发生显著变化时失准 | 在直线运动或曲率变化大时失准 |
短期预测:基于运动学模型或者预测网络,完成短时推演,一般为3s
长期预测:结合意图预测,稳定长时预测,避免远端发散,一般为8s+
基于手工特征的意图预测
基于SVM的意图分类
基于神经网络的意图预测
基于模型的轨迹预测
| 曲线类型 | 优点 | 缺点 |
|---|---|---|
| 贝塞尔曲线 | 可以通过少量的控制点来描述曲线,难以修改,而且计算简单 | 难以修改,一个控制点的变化会影响整条曲线 |
| B样条曲线 | 具有局部性和一定程度的平滑性,可以自定义阶次,移动控制点仅仅改变曲线的部分形状 | 在复杂情况下计算难度大,对于拥有很多控制点的复杂曲线,B样条曲线需要更高阶的多项式,合并两条曲线也比较困难 |
| 卡尔曼滤波 | 可以处理非线性系统,同时可以处理多维度的数据 | 需要对系统建立数学模型,而且对于非线性系统,需要使用扩展卡尔曼滤波等变种算法 |
相关知识
自动驾驶中的车辆运动学模型
以后轴为原点的车辆运动学模型
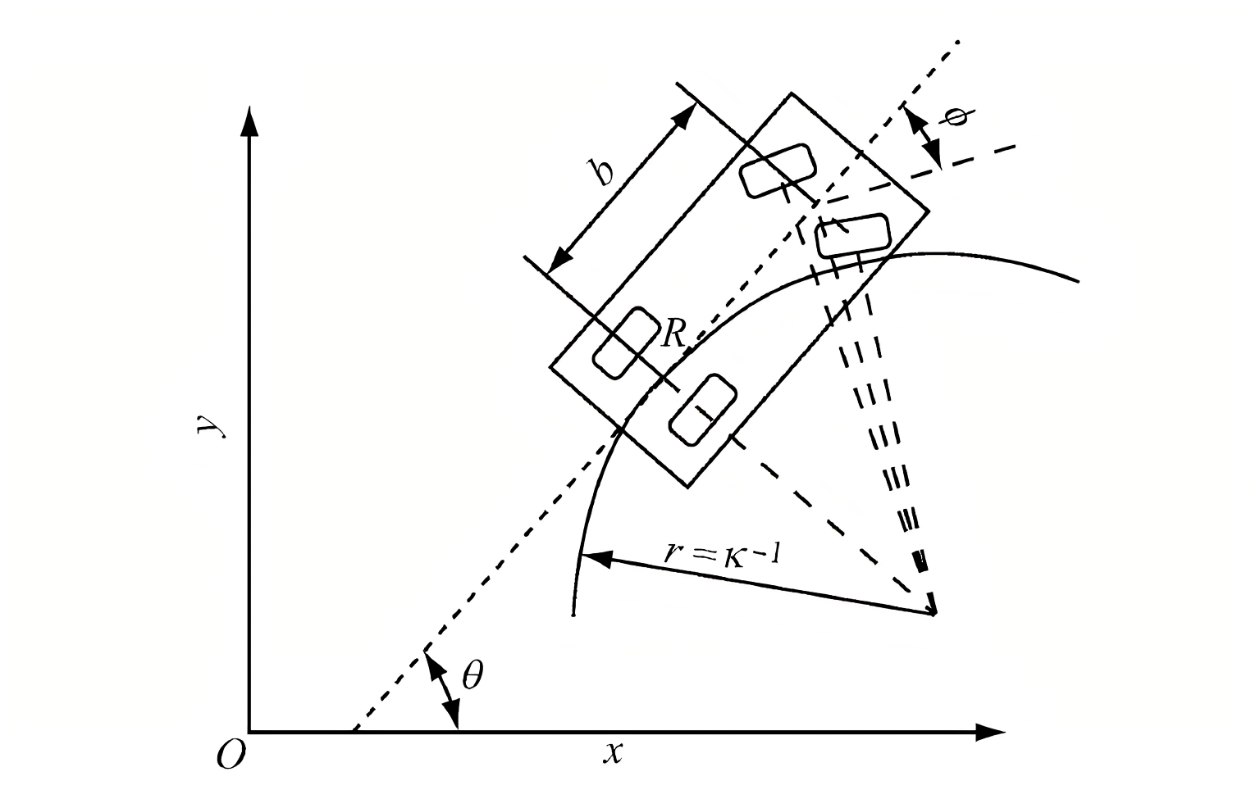
参数
$(x, y, \theta)$:车辆状态信息,分别为坐标位置以及朝向
$b$:车身长度
$\phi$:车轮转向角
$r$:车轮转向角为$\phi$时的半径
推导
求$\dot{x}, \dot{y}, \dot{\theta}$分别为横向速度、纵向速度、角速度
令$s$表示车辆的速度,$\omega$为车辆位移
有
可得
车辆短时位移
且
所以有
两边同时除以$\mathrm{d} t$,且有
可得
综上
卡尔曼滤波
卡尔曼滤波是一种利用线性系统状态方程,通过系统输入输出观测数据,对系统状态进行最优估计的算法。由于观测数据中包括系统中的噪声和干扰的影响,所以最优估计也可看作是滤波过程。
支持向量机
支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。
SVM学习的基本想法是求解能够正确划分训练数据集并且几何间隔最大的分离超平面。如下图所示, 即为分离超平面,对于线性可分的数据集来说,这样的超平面有无穷多个(即感知机),但是几何间隔最大的分离超平面却是唯一的。