TSP-RL
文档维护:Arvin
网页部署:Arvin
▶
TSP
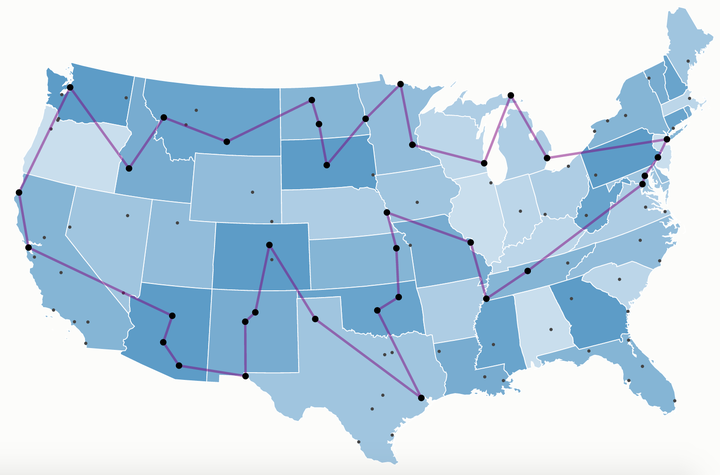
TSP问题(Traveling Salesman Problem),是数学领域中著名问题之一。假设有一个旅行商人要拜访n个城市,他必须选择所要走的路径,路径的限制是每个城市只能拜访一次,而且最后要回到原来出发的城市。路径的选择目标是要求所选的路径路程为所有路径中的最小值。
从图论的角度来看,TSP问题的输入是一个边带权的完全图,目标是找一个权值和最小的哈密顿回路。TSP问题可大致分为对称TSP问题和非对称TSP问题。所谓对称指的是在模型中,城市 u 到城市 v 的距离与城市 v 到城市 u 的距离是一样的,其在图中的体现就是对称TSP问题的输入一般是无向图,而非对称TSP问题的输入往往是有向图。本文主要讨论的是对称TSP问题。
假设给定一个 n 个点的带权完全图 G ,本文需要找到它权值和最小的哈密顿回路。或许会有人觉得这是求最短路,但是这并不是求最短路。最短路是求两点之间权值和最小的路径,而TSP求的是一个回路,并不能直接通过求解最短路进行求解。所有可能的路线共有$(n−1){!}$ 种
下面是两篇经典的使用神经网络和强化学习解决TSP的文章。
Pointer Networks
Abstract
本文引入了一种新的神经网络结构来学习输出序列的学习概率,输出序列的元素是与输入序列中的位置相对应的离散tokens。相比于现有的方法,比如Seq2Seq和Neural Turing Machines,可以解决输入点和输出点的数量是不固定的问题。传统的seq2seq模型无法解决输出序列的词汇表会随着输入序列长度的改变而改变的问题,因为有些问题在输出的每一步中目标输出的数量取决于输入的长度,而输入的长度是可变的。 诸如对可变大小的序列进行排序等问题,以及各种组合优化问题都属于这类问题。对于这类问题,输出往往是输入集合的子集或者输出等于输入。
此外添加了注意力机制 Soft Attention, Self-Attention可以解决信息过长,信息丢失的问题。
Intorduction
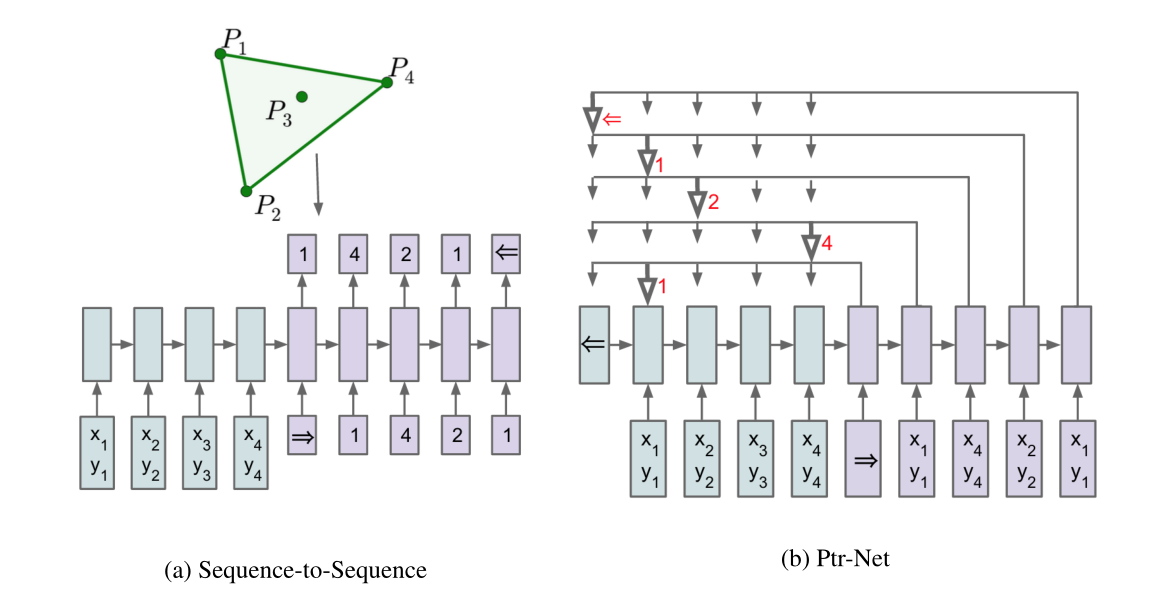
本文提出了一种新的架构,称之为指针网络。它通过使用softmax概率分布作为“指针”来处理表示可变长度字典的基本问题。
本文将指针网络模型应用于涉及几何的三个不同的non-trivial algorithmic problems。证明了学习模型可以应用到比训练集含有更多点的测试集上。
本文的指针网络模型学习了一个小规模(n≤50)TSP近似解算器。本文的研究结果表明,纯数据驱动的方法可以学习计算上难以解决的问题的近似解。
Models
Sequence-to-Sequence model
给定一个训练对$(\mathcal{P},\mathcal{C}^{\mathcal{P}})$,Seq2Seq模型计算条件概率$p(\mathcal{C}^{\mathcal{P}}|\mathcal{P};\theta)$使用RNN网络估计概率链式的项
这里的$\mathcal{P}=\{P_{1},\ldots,P_{n}\}$是一个n维向量,$\mathcal{C}^{\mathcal{P}}=\{C_1,\ldots,C_{m(\mathcal{P})}\}$是$m(\mathcal{P})$维序列,它的长度在$1-n$之间。
通过最大化训练集的条件概率来学习模型的参数,即
Content Based Input Attention
假设编码器(encode)的Hidden State输出为$(e_1, e_2, … , e_n)$
解码器(decoder)的Hidden State输出为$\left(d_{1}, \ldots, d_{m(\mathcal{P})}\right)$,
那么在解码器第i步的注意力计算如下:
即先计算解码器第$i$步和编码器第$j$步的注意力权重,然后使用softmax归一化成具体的概率,最后对于编码器的每一步hidden state进行加权求和。最后计算每一步的具体输出时使用$\text { concatenate }\left[d_{i}, d_{i}^{\prime}\right]$。
Ptr-Net
指针网络相对于Seq2Seq,修改了注意力的计算方式。具体如下:
仅仅使用了Seq2Seq注意力机制的前两步,计算解码器第$i$步和编码器第$j$步的注意力权重,然后归一化成具体的概率。最后直接根据归一化的结果,每一步最大的概率,就指向了输入序列中的具体的某个词,将这个词直接作为编码器第$i$步的输出。
所以和Seq2Seq相比,Seq2Seq利用注意力生成编码器的hidden state,然后输出针对词汇表的概率分布,而Ptr-Net则是输出针对输入序列文本的概率分布。
Empirical Results
本文分别在三个问题上做了实验验证和数据分析,分别是凸包问题(convex hull)、德劳内三角(Delaunay triangulation)和旅行商问题(Travelling Salesman Problem)。这里只贴出TSP的数据结果。
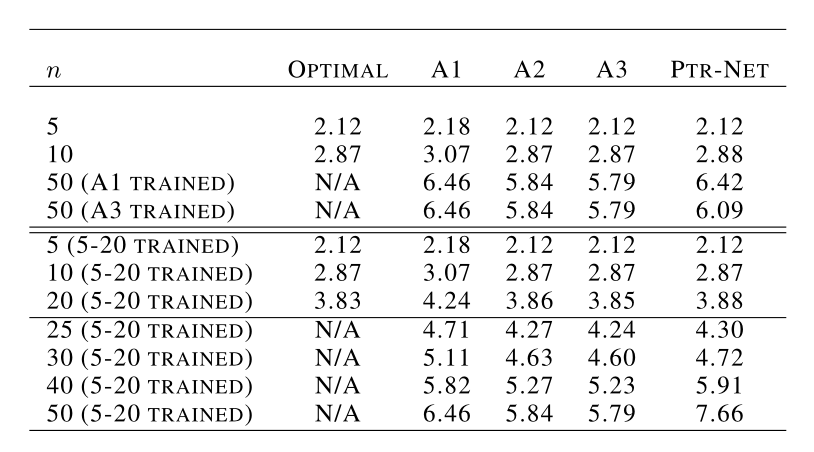
A1、A2是tsp求解器,A3是Christofids算法。
Neural Combinatotial Optimization with Reinforcement Learning
Abstract
本文提出了一个使用神经网络和强化学习来解决组合优化问题的框架。本文专注于旅行推销员问题(TSP),并训练一个递归神经网络,给定一组城市坐标,预测不同城市排列的分布。以负行程长度为奖励信号,采用策略梯度法对递归神经网络的参数进行优化。本文将在一组训练图上学习网络参数与在单个测试图上学习网络参数进行比较。尽管计算成本高,但不需要太多的工程和启发式设计,神经组合优化在多达100个节点的二维欧几里得图上获得了接近最优的结果。同样的方法也适用于另一个np困难问题——背包问题,该问题的最优解为最多200个物品。
Introduction
针对TSP问题,本文基于Ptr-nets,设计了基于PN-AC(actor- critic)的预训练方法(测试时参数不变,AC用于更新策略梯度变化的b(s);
此外本文还考虑了greedy,随机采样以及基于温度的随机采样方法),以及pretraining-activate search(训练好之后,基于测试数据再进行fine-tuning);
- 此外还测试了不带pretraining的activate search(通过train and error的方式improve)
事实上,单纯的指针网络(Pointer Networks)不适用大多数组合优化问题,由于监督学习不适用于大多数组合优化问题,因为无法获得最优标签,即便使用optimal solutions训练监督学习模型,相比较RL的自动寻优机制,SL的泛化性能比较差。因此,本文提出了两种RL方式:
第一种RL 预训练,先在训练集上通过RL训练出一个较好的模型,然后固定参数,在测试集上直接使用;
第二种就是active search,没有pretraining,从随机策略(random policy)开始,在单个测试实例上迭代优化 RNN 参数,再次使用预期的奖励目标,同时跟踪搜索期间采样的最佳解决方案。与第一种不同的是,会不断优化,没有训练、测试数据集之分。
Neural Network Architecture for TSP
本文主要研究二维欧几里得TSP。给定一个输入图,表示为二维空间$s=\{\mathbf{x}_{i}\}_{i=1}^{n}$中n个城市的序列,其中每个$\mathbf{x}_{i}\in\mathbb{R}^{2}$,本文关心的是找到序列$\pi$,称为巡回,访问每个城市一次并且总长度最小。本文定义由置换$\pi$定义的游的长度为:
本文的目的是学习随机策略$p(\pi|s)$的参数,该策略给定点集合$s$的输入,将高概率分配给短行程,低概率分配给长行程。本文的神经网络架构使用链式法则将旅行的概率分解为:
然后使用独立softmax模块表示上式的RHS。
Optimization with Policy Gradients
Actor-Critic
使用model-free的基于策略的强化学习来优化指针网络的参数。训练目标是期望的行程长度,给定输入的graph s,它被定义为:
在训练过程中,从graph s中采样,即$J(\boldsymbol{\theta})=\mathbb{E}_{s\sim\mathcal{S}}J(\boldsymbol{\theta}\mid s)$。
采用策略梯度法和随机梯度下降法对参数进行优化,如下:
算法伪代码:
 其中$b(s)$表示不依赖于$\pi$的基线函数,并估计期望的行程长度以减小梯度的方差。
其中$b(s)$表示不依赖于$\pi$的基线函数,并估计期望的行程长度以减小梯度的方差。
通过绘制样本图$s_{1},s_{2},\ldots,s_{B}\sim\mathcal{S}$,每个图采样一次,即$\pi_{i}\sim p_{\theta}(.\mid s_{i})$,(8)中的梯度用蒙特卡罗采样近似为:
对于$b(s)$的设计是一个非常重要的部分,一个最普通且很流行的方法就是取网络随着时间获得reward的均值(exponential moving average of the rewards obtained by the network over time),但该方法对于不同的输入图无法区分,并且b在一个batch的所有实例中共享,如果${L}(\pi*|\mathbf{s})>\mathbf{b}$,如果该路径已经是困难图中的最佳路径,但依旧不鼓励。
因此,本文设计了一个actor-critic网络,用于学习在给定输入序列 s中,当前策略$p_{\theta}$找到的期望旅行长度,主要用于预测RL中的baseline,也就是$b(s)$,并且AC在其预测 $b_{\theta_v}(s)$和最近策略采样的实际旅行长度之间的均方误差目标上接受随机梯度下降训练:
本文中的critic包括三个神经网络模块:1)一个LSTM encoder,2)一个LSTM process block,3)一个2-layer的ReLU neural network decoder:
- encoder:编码器和ptr-net一样,将输入序列编码为LSTM中的memory以及hidden state
- process block:每个处理步骤通过memory states来更新hidden state,并将 glimpse 函数的输出作为输入提供给下一个处理步骤,类似于seq2seq的解码器操作
- ReLU NN decoder:获得的hidden state被两个输出分别为 d 维和 1 维的全连接层解码为baseline(b(s))预测(即单个标量)
Search Strategies
Sampling
本文的第一种方法是简单地从随机策略$p_{\theta}(.|s)$中抽样多个候选行程,并选择最短的一个。与启发式求解器相比,不强制模型在过程中采样不同的行程。然而,当从非参数softmax中采样时,本文可以用温度超参数控制采样行程的多样性。这种采样过程比贪婪策略产生了显著的改进,贪婪策略总是选择具有最大概率的索引。
Active Search
与其使用固定模型进行采样,忽略从采样解中获得的奖励信息,不如在推理过程中细化随机策略pθ的参数,以最小化单个测试输入s上的$\mathbb{E}_{\pi\sim p_{\theta}(.|s)}L(\pi\mid s)$。当从训练模型开始时,这种方法被证明特别有竞争力。值得注意的是,当从未经训练的模型开始时,它也会产生令人满意的解决方案。我们将这两种方法称为强化学习预训练-主动搜索和主动搜索,因为模型在单个测试实例上搜索候选解决方案时主动更新其参数。
主动搜索应用策略梯度类似于算法1,但为单个测试输入在候选解$\pi_{1}\ldots\pi_{B}\sim p_{\theta}(\cdot|s)$上绘制蒙特卡罗样本。它采用一种an exponential moving average baseline,而不是评论家,因为不需要区分输入。我们的主动搜索训练算法在算法2中给出。我们注意到,虽然强化学习训练不需要监督,但它仍然需要训练数据,因此泛化取决于训练数据的分布。相比之下,主动搜索是独立于分布的。最后,由于我们将一组城市编码为序列,因此在将输入序列提供给指针网络之前,我们随机打乱输入序列。这增加了抽样过程的随机性,并导致主动搜索的巨大改进。

Experiments
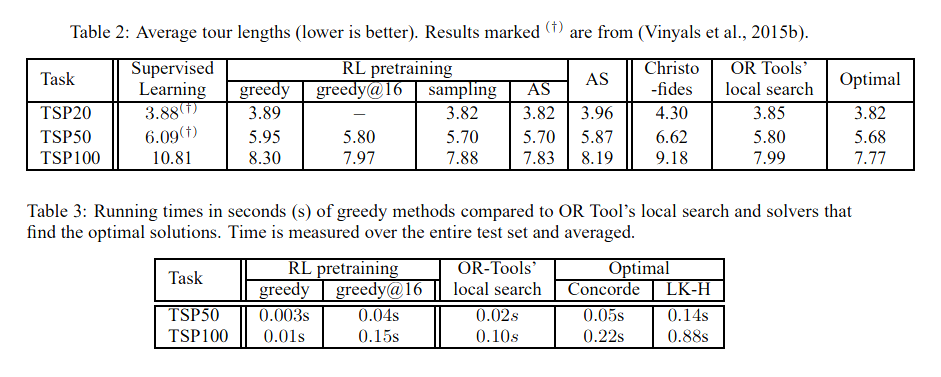
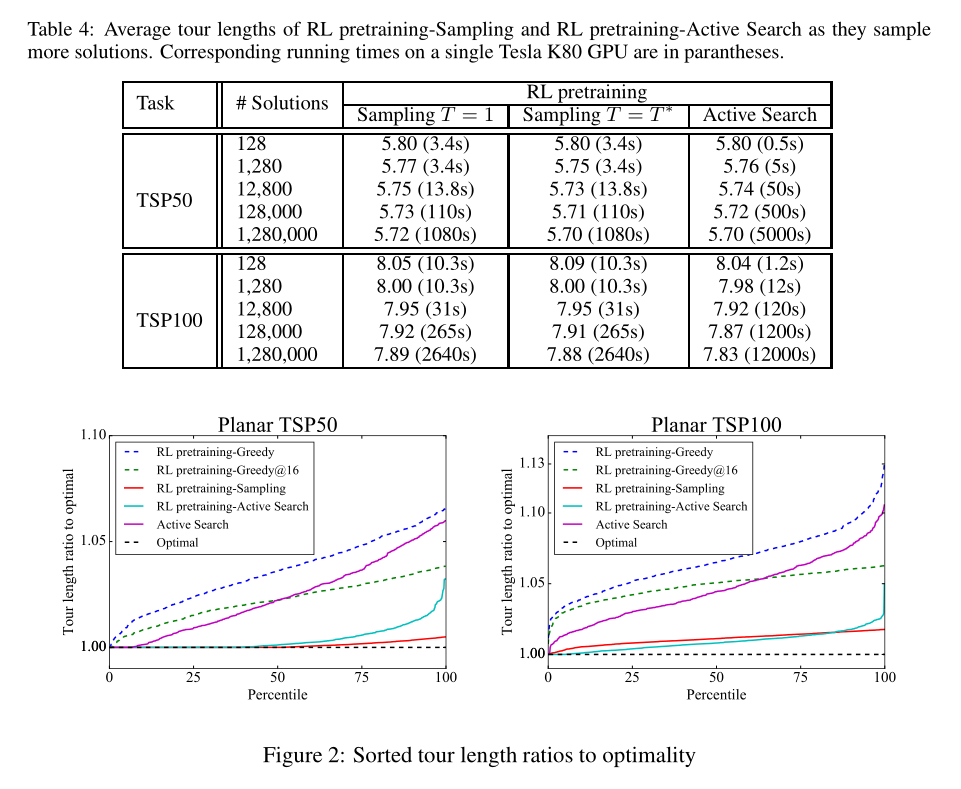
参考链接:【ML4CO论文精读】总结:一些基于Ptr-nets & AM的组合优化模型
参考文献:
Vinyals O, Fortunato M, Jaitly N. Pointer Networks
Bello I, Pham H, Le Q V, et al. Neural Combinatorial Optimization with Reinforcemen Learning